AWS Sagemaker is the heart of machine learning in AWS and is intended to handle the entire machine learning workflow from building, training, and deploying to production. Features ranges from offering Sagemaker notebooks for data preparation and feature engineering to spinning up EC2 instances to train models on large datasets.
Sagemaker Architecture
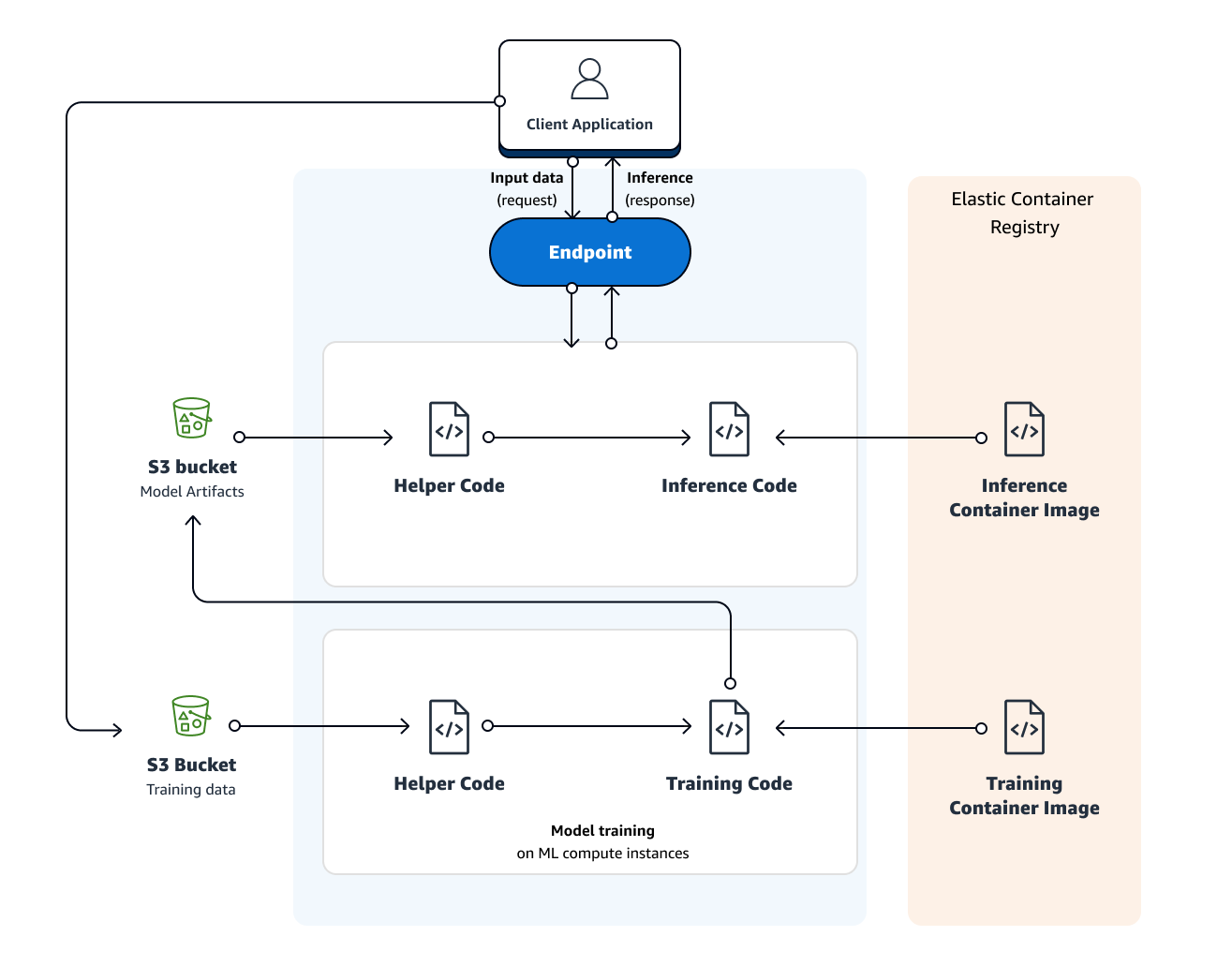
The root of the general architecture of Sagemaker is training data sitting in an S3 bucket (ideally in Protobuf format if to be used for deep learning). The job of Sagemaker is to provision hosts to train that data on. The model itself comes from a Docker image in an Elastic Container Registry (ECR). The training code will be taken from the Docker image and deployed to a fleet of hosts in Sagemaker to do the training. When the training completes Sagemaker will return that trained model to be stored in another S3 bucket. Once the model is ready to be deployed Sagemaker will reference another Docker image in the ECR which contains the inference code. The job of the inference Docker image is to take in incoming requests and use the saved model to make inferences based on that request. Sagemaker will spin up as many hosts as necessary to provide endpoints to the client application and serve incoming requests.
Sagemaker Notebooks
The most common way to use Sagemaker is via a Sagemaker Notebook. Sagemaker Notebook allows you access data from S3, pre-process and analyze that data, and train models. Popular libraries such as scikit learn and TensorFlow may be accessed via a Sagemaker Notebook in addition to Sagemaker’s innate machine learning models which are available out-of-the-box - we will discuss some of these below.
A cool aspect of Sagemaker Notebooks is they allow you to spin up instances directly from the notebook. Furthermore, once training is complete it’s possible to deploy the model to fleet of endpoints directly from the notebook and allowing you make predictions at scale.
Linear Learner
Linear Learner is exactly what it sounds like - Sagemaker’s linear regression algorithm implementation. It can be used for regression tasks or classification when a threshold is specified.
Linear Learner accepts data in either a RecordIO-wrapped Protobuf (float32) or raw CSV format. For the raw CSV format, Linear Learner will assume that the first column is the target variable. Linear Learner accepts training data in either File or Pipe mode. File mode will copy all training data over from S3 all at once while Pipe mode data is streamed directly to training instances rather than being downloaded first. Pipe mode is advantageous when you have larger training sets (especially > 16 TB) as it will enable your jobs to train more quickly and use less disk space.
Linear Learner is farily sophisticated for being a “simple” machine learning model. By using stochastic gradient descent (SGD) it can train large datasets much more quickly. Linear Learner has multiple optimization algorithm options to choose from including Adam and AdaGrad. When training commences, multiple models are trained in parallel and the algorithm chooses the best model during the validation phase. Of course, L1 (Lasso) and L2 (Ridge) regularization options are available to avoid overfitting and/or conduct feature selection.
XGBoost
AWS XGBoost makes use of the currently widely popular and effective eXtreme Gradient Boosting algorithm. The XGBoost algorithm is an iterative, ensemble approach to machine learning which creates “weak leaner” decision trees in succession with each tree being focused on correcting the mistakes made in the previous model. As its name implies, XGBoost uses gradient descent to minimize the loss function as new models are added. XGBoost may be used for classification or regression tasks.
Because AWS is just using the open-source XGBoost algorithm it was not created for Sagemaker. As such, there are a few differences relative to other AWS machine learning tools. For one, XGBoost in Sagemaker is designed to take data in a CSV format as opposed to the AWS standard Protobuf format. Furthermore, models will be serialized / de-serialized using Pickle in Python and may even be used directly within the notebook - there is no requirement to deploy the model to training hosts or use Docker. Of course, for larger train jobs it is possible to refer to the XGBoost Docker image in ECR and deploy it to a fleet of training hosts.
XGBoost’s limiting factor is the computing power rather than memory. As such XGBoost is not a GPU based algorithm and only uses CPU. An ideal instance type for training would be M4.
Seq2Seq
AWS Seq2Seq takes a sequence of tokens (for example, text or audio) and uses RNN’s and CNN’s to output another sequence of tokens. Applications range from language translation to transforming speech to text.
AWS Seq2Seq expects data in the usual Protobus format, however, contrary to other algorithms it expects the data to be inputted in an integer format (as opposed to float). Input data should also be passed in as tokenized text files alongside a vocabulary file. Training a new model can a really long time, even on AWS, thus Seq2Seq provides a variety of pre-trained models which may be used for transfer learning.
As a deep learning algorithm, Seq2Seq is well suited for GPU instance (ideally P3 node) training. Unfortunately, Seq2Seq does not allow parallelized training across multiple machines, however, it can use multiple GPU’s on the same machine.
DeepAR
DeepAR is AWS’s implementation of RNN’s to forecast one-dimensional time series data (stock prices, weather, etc.). A A differentiating feature about DeepAR is that it allows you to train a single model over various time series at once. If you have multiple interdependent time series, DeepAR can learn from the relationships between those time series. As with all RNN’s it has the ability to detect seasonality and frequencies.
DeepAR expects data in a JSON format (Parquet for best performance) with each record in the JSON file including a time stamp and a target. Optionally, the record may also contain a dynamic features (i.e. boolean value of whether or not promotion was applied when modeling sales) and categorical features.
You modeling time series in DeepAR you should look at your entire time series you have available. The model will be trained on the entire time series minus the time points and the model will be tested on the entire time series. If possible, train on many related time series to fully take advantage of DeepAR.
DeepAR may use either a CPU or GPU (CPU could actually work).
BlazingText
Blazing Text is AWS’s implementation of text classification (i.e. predicting labels for a sentence) and word2vector (i.e. find words that are similar to eachother, useful component of other NLP algorithms) algorithms. It should be noted here that Blazing Text should only be used for words and sentences, not entire documents.
Blazing Text’s word2vector algorithm can work in multiple modes. One is “cbow” which stands for Continuous Bag of Words - this is just a bag of words with no particular order. Skip-gram and batch skip-grams are two modes where the order of the words is taken into account.
For cbow and skip-gram any single CPU instance for work. For batch skip-gram you have the option of using multiple CPU instances. For text classification on training sets larger than 2 GB a single GPU instance is recommended.